Introduction
Jupyter notebooks provide interactive, online computational environments, combining blocks of live code with narrative text, and visualisations. They provide a great environment for carrying out interactive exploratory analysis work, and can be managed under version control (i.e. git).
We provide a JupyterHub server, which enable Jupyter notebooks to be run on HPC cluster nodes. This is integrated with the cluster filesystem giving you access to all your centralised data from within the notebook environment, and ensures your work is backed up as part of routine cluster backups.
Accessing JupyterHub
JupyterHub is available to anyone with an HPC cluster account.
- Click here: https://jupyterhub.compbio.dundee.ac.uk
- Enter your UoD credentials (i.e. your standard username, not including the @dundee.ac.uk suffix, and your password) and click the 'Sign In' button.
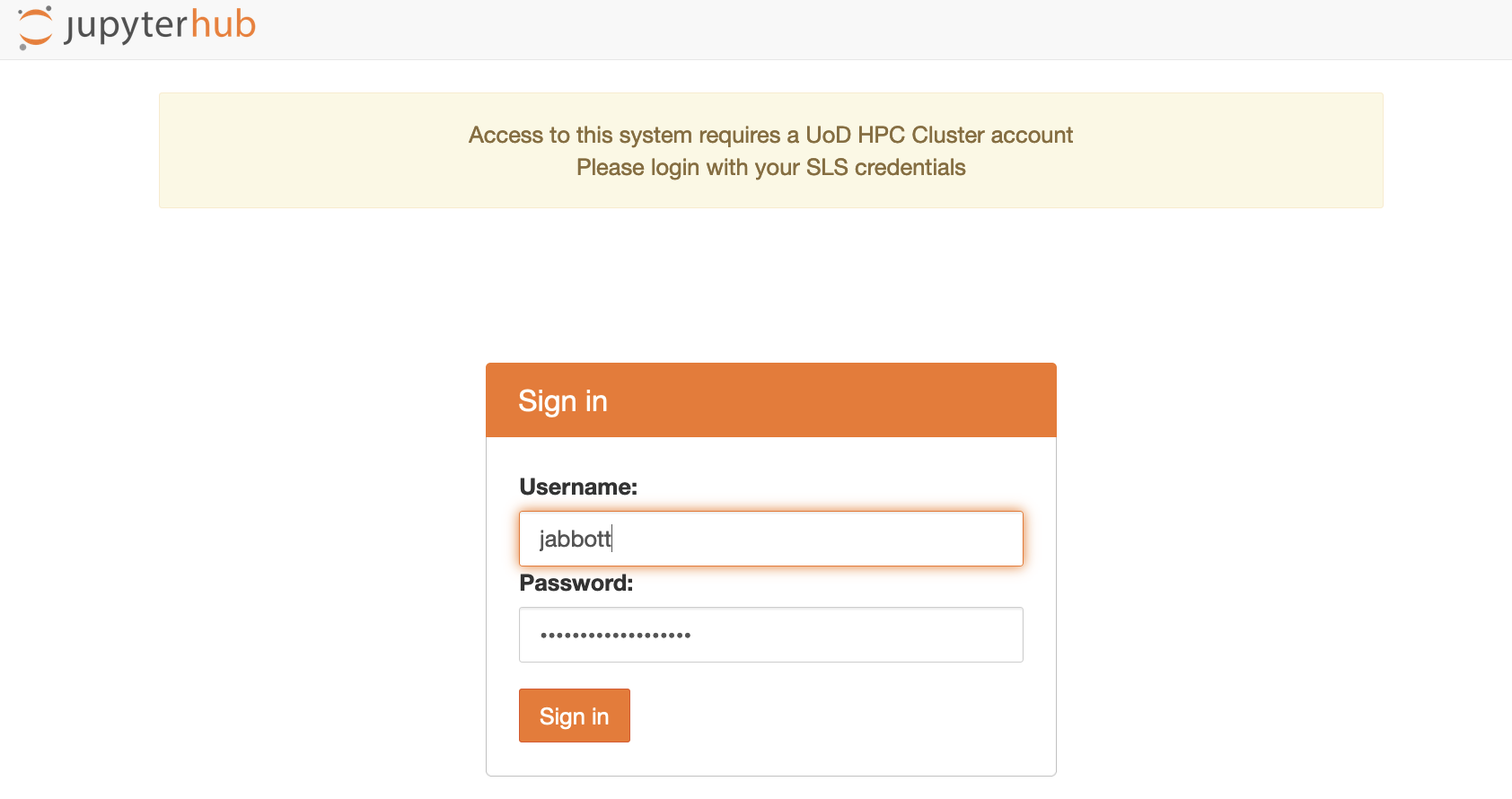
Logging
Conda Integration
Jupyter notebooks integrate with conda environments, enabling you to select an appropriate environment within your notebook. In order to access a conda environment from within a Jupyter notebook, install the 'ipykernel' conda package into the environment you wish to access.